publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- CVIU’25
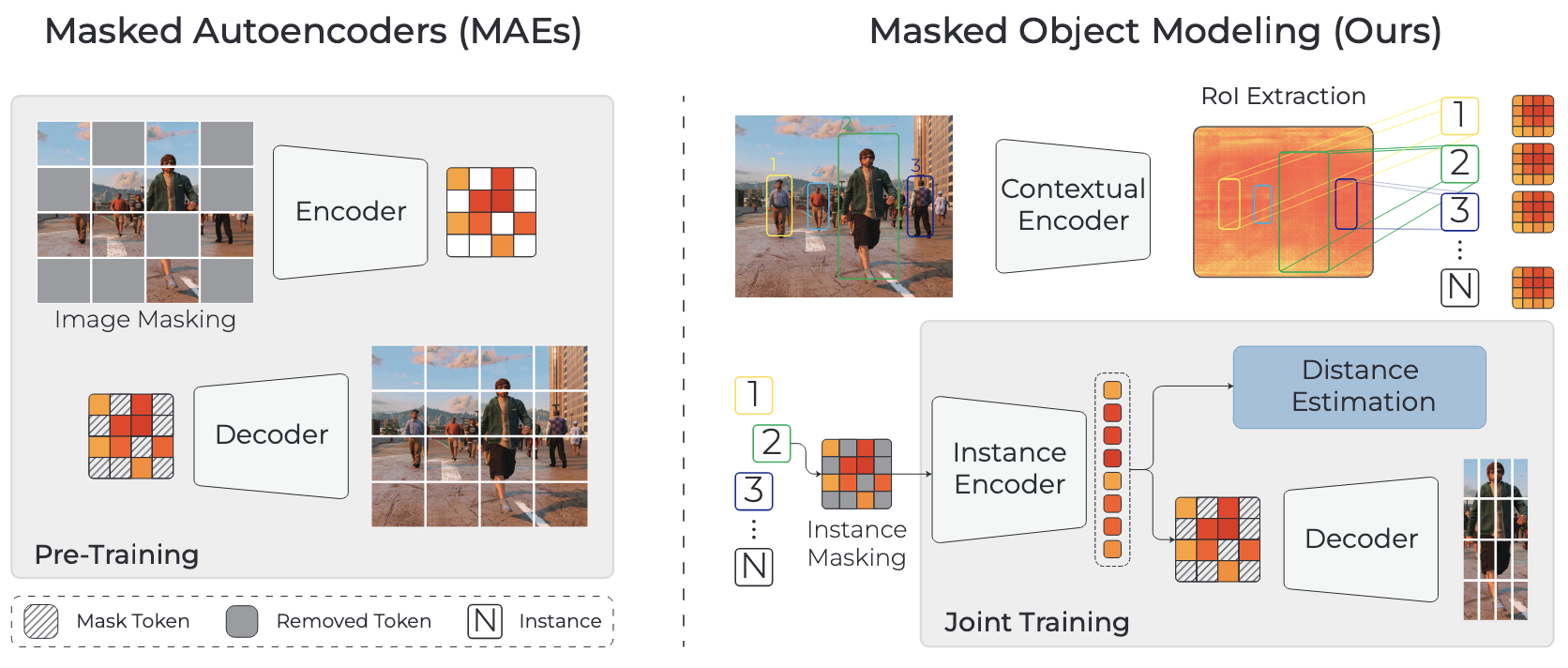 Monocular Per-Object Distance Estimation with Masked Object ModelingAniello Panariello, Gianluca Mancusi, Fedy Haj Ali, and 3 more authorsIn Computer Vision and Image Understanding, 2025
Monocular Per-Object Distance Estimation with Masked Object ModelingAniello Panariello, Gianluca Mancusi, Fedy Haj Ali, and 3 more authorsIn Computer Vision and Image Understanding, 2025Per-object distance estimation is critical in surveillance and autonomous driving, where safety is crucial. While existing methods rely on geometric or deep supervised features, only a few attempts have been made to leverage self-supervised learning. In this respect, our paper draws inspiration from Masked Image Modeling (MiM) and extends it to multi-object tasks. While MiM focuses on extracting global image-level representations, it struggles with individual objects within the image. This is detrimental for distance estimation, as objects far away correspond to negligible portions of the image. Conversely, our strategy, termed Masked Object Modeling (MoM), enables a novel application of masking techniques. In a few words, we devise an auxiliary objective that reconstructs the portions of the image pertaining to the objects detected in the scene. The training phase is performed in a single unified stage, simultaneously optimizing the masking objective and the downstream loss (i.e., distance estimation). We evaluate the effectiveness of MoM on a novel reference architecture (DistFormer) on the standard KITTI, NuScenes, and MOTSynth datasets. Our evaluation reveals that our framework surpasses the SoTA and highlights its robust regularization properties. The MoM strategy enhances both zero-shot and few-shot capabilities, from synthetic to real domain. Finally, it furthers the robustness of the model in the presence of occluded or poorly detected objects.
@inproceedings{panariello2025Monocular, title = {Monocular Per-Object Distance Estimation with Masked Object Modeling}, author = {Panariello, Aniello and Mancusi, Gianluca and Haj Ali, Fedy and Porrello, Angelo and Calderara, Simone and Cucchiara, Rita}, booktitle = {Computer Vision and Image Understanding}, year = {2025}, } - BMVC’25
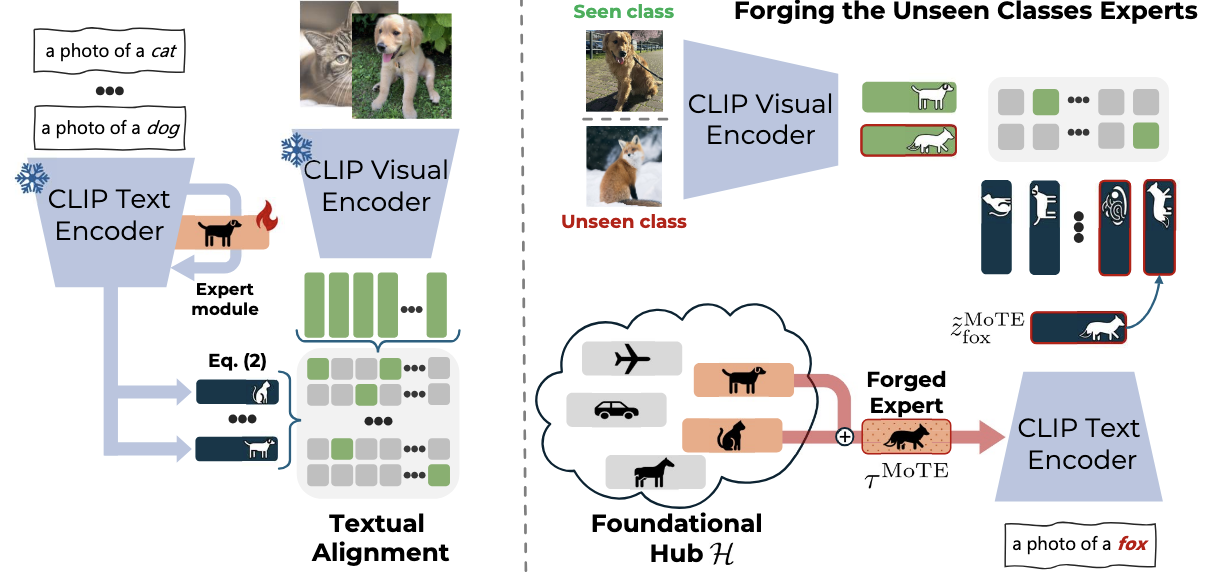 Modular Embedding Recomposition for Incremental LearningAniello Panariello, Emanuele Frascaroli, Pietro Buzzega, and 3 more authorsIn British Machine Vision Conference, 2025
Modular Embedding Recomposition for Incremental LearningAniello Panariello, Emanuele Frascaroli, Pietro Buzzega, and 3 more authorsIn British Machine Vision Conference, 2025The advent of pre-trained Vision-Language Models (VLMs) has significantly transformed Continual Learning (CL), mainly due to their zero-shot classification abilities. Such proficiency makes VLMs well-suited for real-world applications, enabling robust performance on novel unseen classes without requiring adaptation. However, fine-tuning remains essential when downstream tasks deviate significantly from the pre-training domain. Prior CL approaches primarily focus on preserving the zero-shot capabilities of VLMs during incremental fine-tuning on a downstream task. We take a step further by devising an approach that transforms preservation into enhancement of the zero-shot capabilities of VLMs. Our approach, named MoDular Embedding Recomposition (MoDER), introduces a modular framework that trains multiple textual experts, each specialized in a single seen class, and stores them in a foundational hub. At inference time, for each unseen class, we query the hub and compose the retrieved experts to synthesize a refined prototype that improves classification. We show the effectiveness of our method across two popular zero-shot incremental protocols, Class-IL and MTIL, comprising a total of 14 datasets.
@inproceedings{panariello2025modular, title = {Modular Embedding Recomposition for Incremental Learning}, author = {Panariello, Aniello and Frascaroli, Emanuele and Buzzega, Pietro and Bonicelli, Lorenzo and Porrello, Angelo and Calderara, Simone}, booktitle = {British Machine Vision Conference}, year = {2025}, } - NeurIPS’25
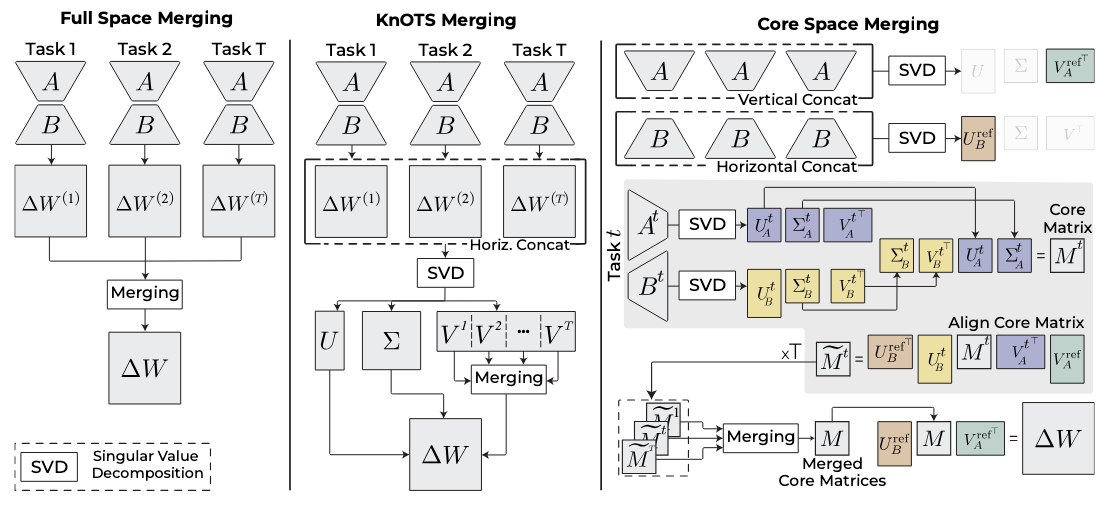 Accurate and Efficient Low-Rank Model Merging in Core SpaceAniello Panariello, Daniel Marczak, Simone Magistri, and 5 more authorsIn Advances in Neural Information Processing Systems, 2025
Accurate and Efficient Low-Rank Model Merging in Core SpaceAniello Panariello, Daniel Marczak, Simone Magistri, and 5 more authorsIn Advances in Neural Information Processing Systems, 2025In this paper, we address the challenges associated with merging low-rank adaptations of large neural networks. With the rise of parameter-efficient adaptation techniques, such as Low-Rank Adaptation (LoRA), model fine-tuning has become more accessible. While fine-tuning models with LoRA is highly efficient, existing merging methods often sacrifice this efficiency by merging fully-sized weight matrices. We propose the Core Space merging framework, which enables the merging of LoRA-adapted models within a common alignment basis, thereby preserving the efficiency of low-rank adaptation while substantially improving accuracy across tasks. We further provide a formal proof that projection into Core Space ensures no loss of information and provide a complexity analysis showing the efficiency gains. Extensive empirical results demonstrate that Core Space significantly improves existing merging techniques and achieves state-of-the-art results on both vision and language tasks while utilizing a fraction of the computational resources.
@inproceedings{panariello2025accurate, title = {Accurate and Efficient Low-Rank Model Merging in Core Space}, author = {Panariello, Aniello and Marczak, Daniel and Magistri, Simone and Porrello, Angelo and Twardowski, Bart{\l}omiej and Bagdanov, Andrew D. and Calderara, Simone and van de Weijer, Joost}, booktitle = {Advances in Neural Information Processing Systems}, year = {2025}, }



2024
- ICPR’24
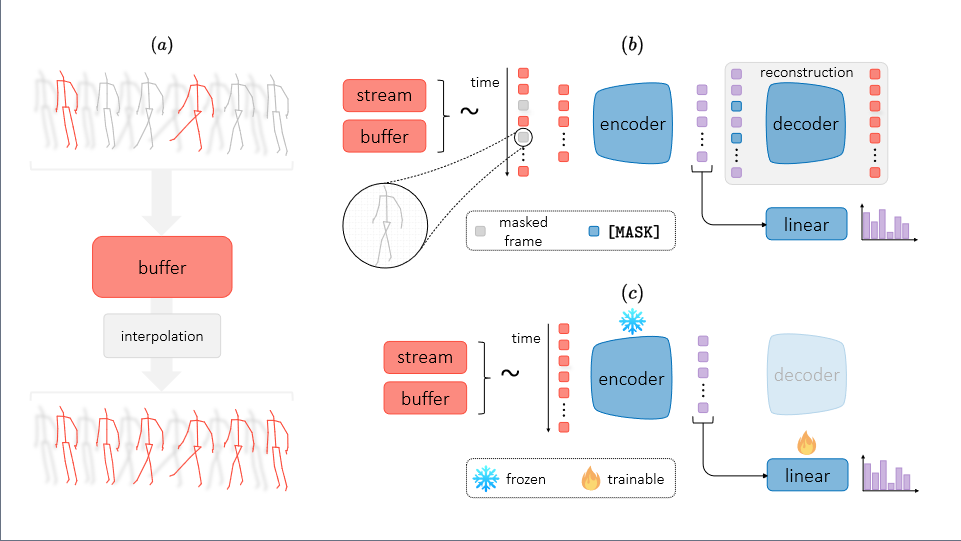 Mask and Compress: Efficient Skeleton-based Action Recognition in Continual LearningMatteo Mosconi, Andriy Sorokin, Aniello Panariello, and 6 more authorsIn International Conference on Pattern Recognition, 2024
Mask and Compress: Efficient Skeleton-based Action Recognition in Continual LearningMatteo Mosconi, Andriy Sorokin, Aniello Panariello, and 6 more authorsIn International Conference on Pattern Recognition, 2024Oral Presentation
The use of skeletal data allows deep learning models to perform action recognition efficiently and effectively. Herein, we believe that exploring this problem within the context of Continual Learning is crucial. While numerous studies focus on skeleton-based action recognition from a traditional offline perspective, only a handful venture into online approaches. In this respect, we introduce CHARON (Continual Human Action Recognition On skeletoNs), which maintains consistent performance while operating within an efficient framework. Through techniques like uniform sampling, interpolation, and a memory-efficient training stage based on masking, we achieve improved recognition accuracy while minimizing computational overhead. Our experiments on Split NTU-60 and the proposed Split NTU-120 datasets demonstrate that CHARON sets a new benchmark in this domain. The code is available at https://github.com/Sperimental3/CHARON.
@inproceedings{mosconi2024mask, title = {Mask and Compress: Efficient Skeleton-based Action Recognition in Continual Learning}, author = {Mosconi, Matteo and Sorokin, Andriy and Panariello, Aniello and Porrello, Angelo and Bonato, Jacopo and Cotogni, Marco and Sabetta, Luigi and Calderara, Simone and Cucchiara, Rita}, booktitle = {International Conference on Pattern Recognition}, year = {2024}, } - BMVC’24
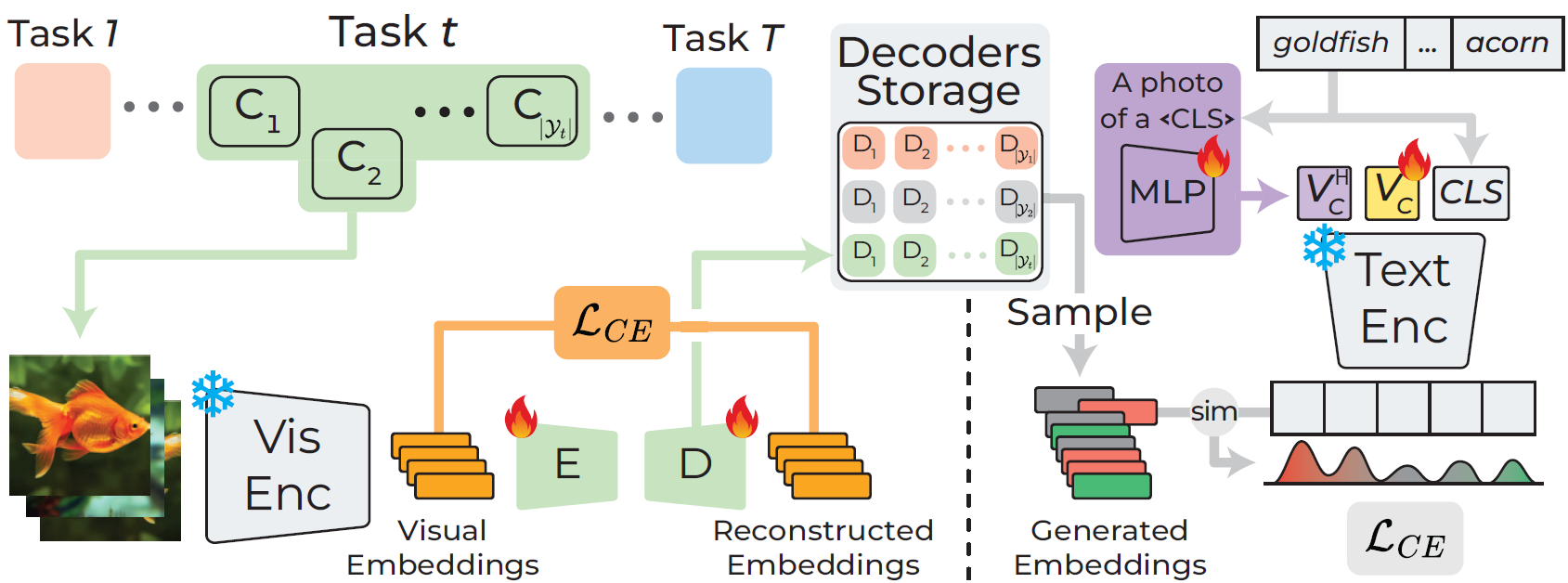 CLIP with Generative Latent Replay: a Strong Baseline for Incremental LearningEmanuele Frascaroli, Aniello Panariello, Pietro Buzzega, and 3 more authorsIn British Machine Vision Conference, 2024
CLIP with Generative Latent Replay: a Strong Baseline for Incremental LearningEmanuele Frascaroli, Aniello Panariello, Pietro Buzzega, and 3 more authorsIn British Machine Vision Conference, 2024Oral Presentation
With the emergence of Transformers and Vision-Language Models (VLMs) such as CLIP, large pre-trained models have become a common strategy to enhance performance in Continual Learning scenarios. This led to the development of numerous prompting strategies to effectively fine-tune transformer-based models without succumbing to catastrophic forgetting. However, these methods struggle to specialize the model on domains significantly deviating from the pre-training and preserving its zero-shot capabilities. In this work, we propose **Continual Generative training for Incremental prompt-Learning**, a novel approach to mitigate forgetting while adapting a VLM, which exploits generative replay to align prompts to tasks. We also introduce a new metric to evaluate zero-shot capabilities within CL benchmarks. Through extensive experiments on different domains, we demonstrate the effectiveness of our framework in adapting to new tasks while improving zero-shot capabilities. Further analysis reveals that our approach can bridge the gap with joint prompt tuning. The codebase is available at https://github.com/aimagelab/mammoth.
@inproceedings{frascaroli2024CLIP, author = {Frascaroli, Emanuele and Panariello, Aniello and Buzzega, Pietro and Bonicelli, Lorenzo and Porrello, Angelo and Calderara, Simone}, title = {CLIP with Generative Latent Replay: a Strong Baseline for Incremental Learning}, booktitle = {British Machine Vision Conference}, year = {2024}, } - NeurIPS’24
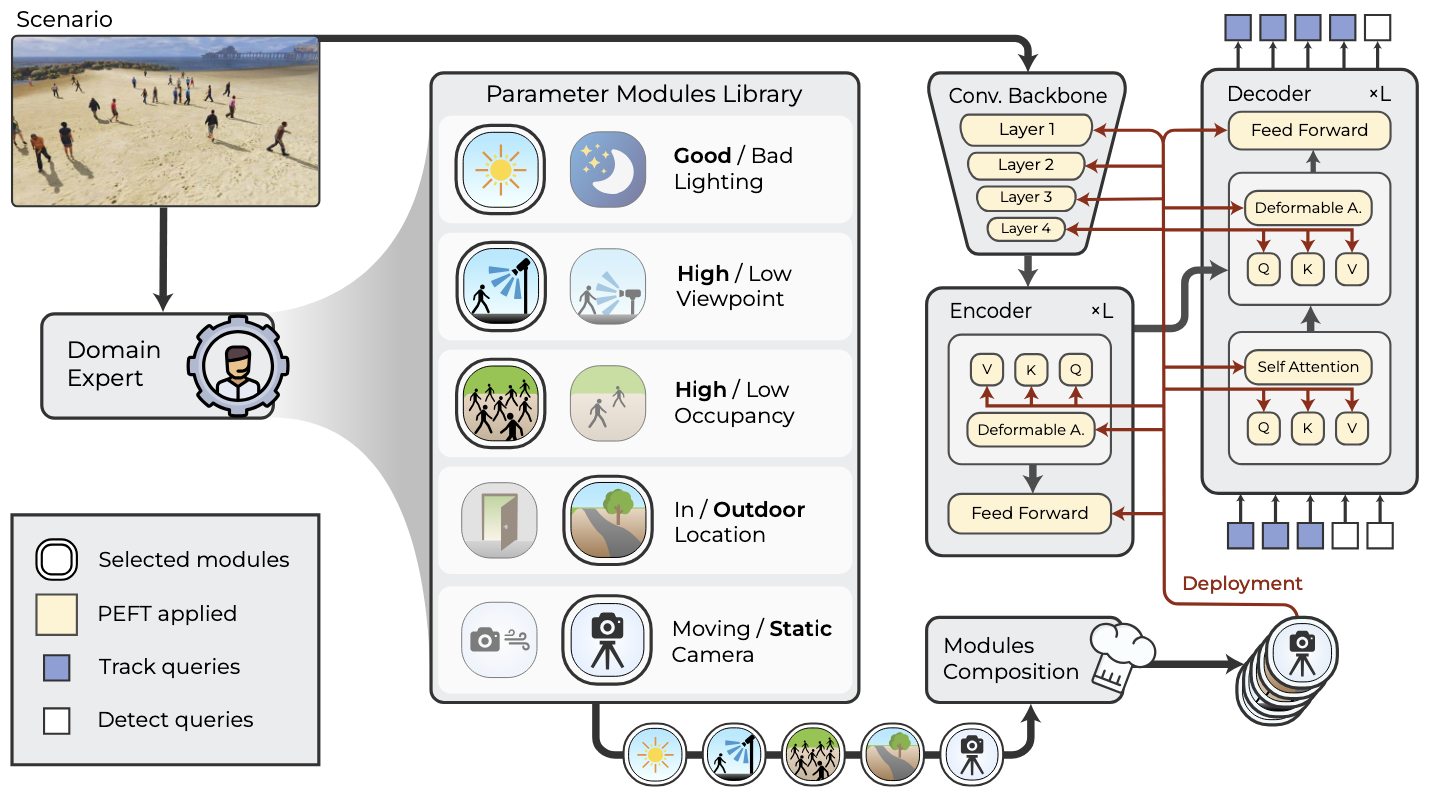 Is Multiple Object Tracking a Matter of Specialization?Gianluca Mancusi, Mattia Bernardi, Aniello Panariello, and 3 more authorsIn Advances in Neural Information Processing Systems, 2024
Is Multiple Object Tracking a Matter of Specialization?Gianluca Mancusi, Mattia Bernardi, Aniello Panariello, and 3 more authorsIn Advances in Neural Information Processing Systems, 2024End-to-end transformer-based trackers have achieved remarkable performance on most human-related datasets. However, training these trackers in heterogeneous scenarios poses significant challenges, including negative interference - where the model learns conflicting scene-specific parameters - and limited domain gener- alization, which often necessitates expensive fine-tuning to adapt the models to new domains. In response to these challenges, we introduce Parameter-efficient Scenario-specific Tracking A rchitecture (PASTA), a novel framework that com- bines Parameter-Efficient Fine-Tuning (PEFT) and Modular Deep Learning (MDL). Specifically, we define key scenario attributes (e.g., camera-viewpoint, lighting condition) and train specialized PEFT modules for each attribute. These expert modules are combined in parameter space, enabling systematic generalization to new domains without increasing inference time. Extensive experiments on MOT- Synth, along with zero-shot evaluations on MOT17 and PersonPath22 demonstrate that a neural tracker built from carefully selected modules surpasses its monolithic counterpart.
@inproceedings{mancusi2024is, author = {Mancusi, Gianluca and Bernardi, Mattia and Panariello, Aniello and Porrello, Angelo and Calderara, Simone and Cucchiara, Rita}, title = {Is Multiple Object Tracking a Matter of Specialization?}, booktitle = {Advances in Neural Information Processing Systems}, year = {2024}, }



2023
- ICCV’23
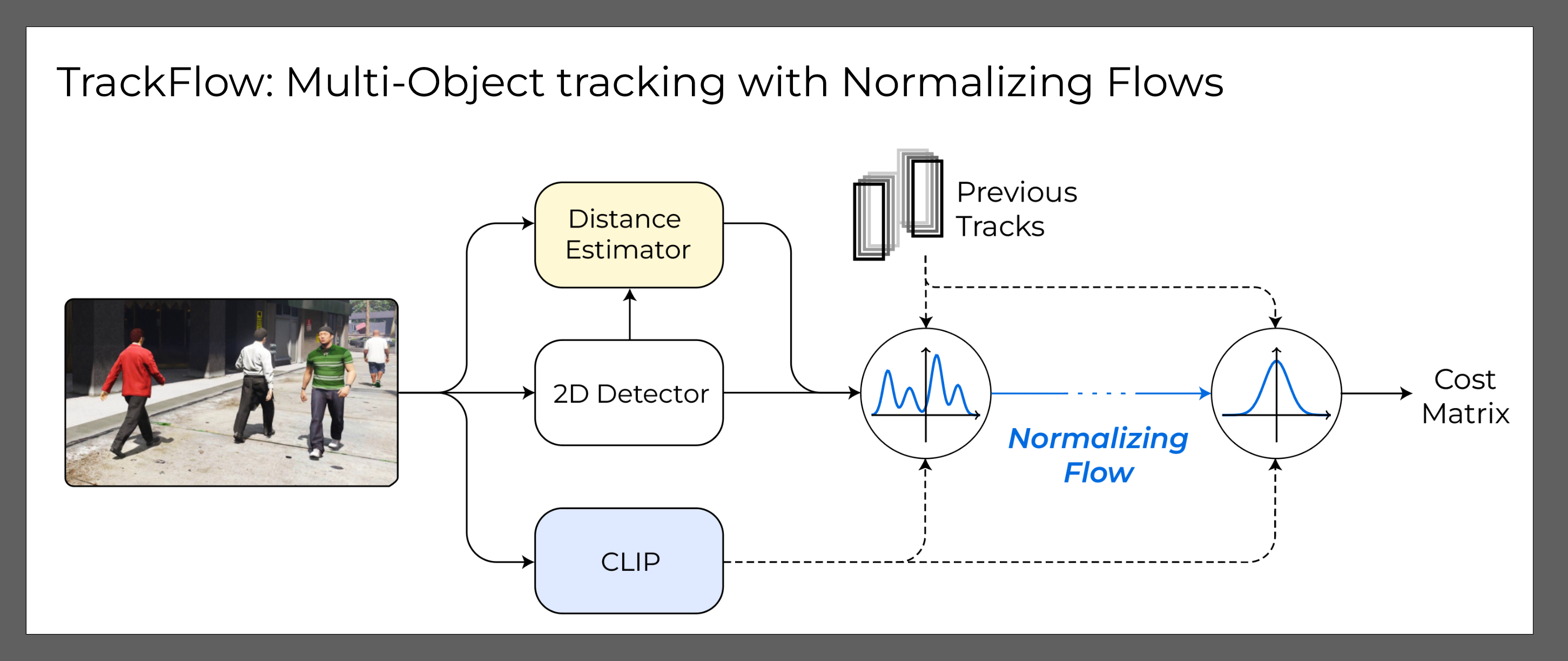 TrackFlow: Multi-Object tracking with Normalizing FlowsGianluca Mancusi, Aniello Panariello, Angelo Porrello, and 3 more authorsIn International Conference on Computer Vision, 2023
TrackFlow: Multi-Object tracking with Normalizing FlowsGianluca Mancusi, Aniello Panariello, Angelo Porrello, and 3 more authorsIn International Conference on Computer Vision, 2023The multi-object tracking field has recently seen a renewed interest in the good old schema of *tracking-by-detection*, as its simplicity and strong priors spare it from the complex design and painful babysitting of *tracking-by-attention* approaches. In view of this, we aim at extending tracking-by-detection to **multi-modal** settings, where a comprehensive cost has to be computed from heterogeneous information *e.g.* 2D motion cues, visual appearance, and pose estimates. More precisely, we follow a case study where a rough estimate of 3D information is also available and must be merged with other traditional metrics (*e.g.*, the IoU). To achieve that, recent approaches resort to either simple rules or complex heuristics to balance the contribution of each cost. However, *i)* they require careful tuning of tailored hyperparameters on a hold-out set, and *ii)* they imply these costs to be independent, which does not hold in reality. We address these issues by building upon an elegant probabilistic formulation, which considers the cost of a candidate association as the *negative log-likelihood* yielded by a deep density estimator trained to model the conditional joint probability distribution of correct associations. Our experiments, conducted on both simulated and real benchmarks, show that our approach consistently enhances the performance of several tracking-by-detection algorithms.
@inproceedings{mancusi2023Trackflow, title = {TrackFlow: Multi-Object tracking with Normalizing Flows}, author = {Mancusi, Gianluca and Panariello, Aniello and Porrello, Angelo and Fabbri, Matteo and Calderara, Simone and Cucchiara, Rita}, booktitle = {International Conference on Computer Vision}, year = {2023}, }

2022
- ECCVW’22
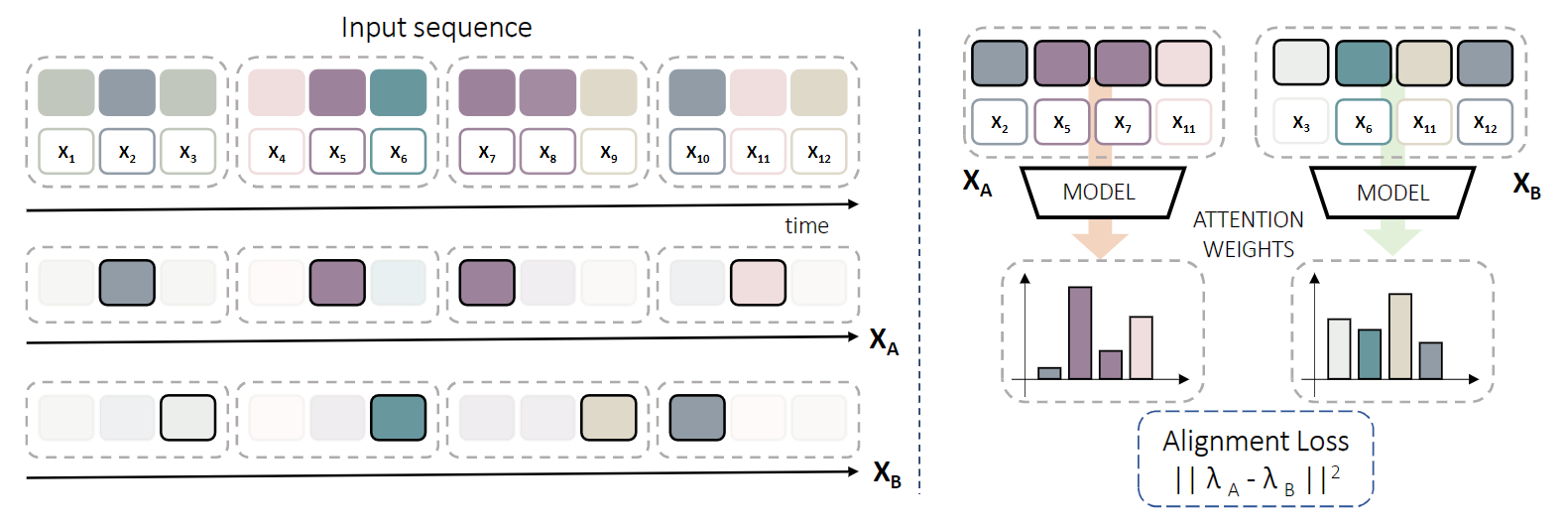 Consistency based Self-supervised Learning for Temporal Anomaly LocalizationAniello Panariello, Angelo Porrello, Simone Calderara, and 1 more authorIn European Conference on Computer Vision Workshops, 2022
Consistency based Self-supervised Learning for Temporal Anomaly LocalizationAniello Panariello, Angelo Porrello, Simone Calderara, and 1 more authorIn European Conference on Computer Vision Workshops, 2022This work tackles Weakly Supervised Anomaly detection, in which a predictor is allowed to learn not only from normal examples but also from a few labeled anomalies made available during training. In particular, we deal with the localization of anomalous activities within the video stream: this is a very challenging scenario, as training examples come only with video-level annotations (and not frame-level). Several recent works have proposed various regularization terms to address it *i.e.* by enforcing sparsity and smoothness constraints over the weakly-learned frame-level anomaly scores. In this work, we get inspired by recent advances within the field of self-supervised learning and ask the model to yield the same scores for different augmentations of the same video sequence. We show that enforcing such an alignment improves the performance of the model on XD-Violence.
@inproceedings{panariello2022consistency, title = {Consistency based Self-supervised Learning for Temporal Anomaly Localization}, author = {Panariello, Aniello and Porrello, Angelo and Calderara, Simone and Cucchiara, Rita}, booktitle = {European Conference on Computer Vision Workshops}, year = {2022}, }
